


 22 min
22 min




Joins are NOT Expensive! - Raw Reading
When talking about Data Lakes and how people access them - we must address some of the misconceptions that made them popular in the first place.
One of the largest misconceptions is this: "Joins are expensive". It is apparently believed (as I discovered from discussions on LinkedIn) that it costs less CPU to turn your data model into a flat table and serve that to users - than it does to join everytime you access the table.
It is certainly true that object stores allow nearly infinite I/O (although at a very high CPU cost to handle the HTTP overhead) and nearly infinite storage. But, is there really such a thing as "sacrificing disk space to save the CPU cost of joins?"
Today, let us put this to the test.
Test Setup
Consider two, competing data models:
- A traditional, dimensional data model where we keep the attributes of products in their own
producttable and join tosaleseverytime we want to retrieve data (via anid_productprimary / foreign key). - The "One Big Table" model where we pre-join product columns into a large, flat
sales_obttable and always access the data via aSELECTthat has no joins
Obviously, the second table is more expensive to construct in your pipeline or whatever you call ETL these days to sound like you're innovative.
But, which one of the two models uses the least CPU when we access it for reads?
The "Traditional" dimensional model
Our data model is:
CREATE TABLE product (
id_product INT NOT NULL PRIMARY KEY
, c01 VARCHAR
, c02 VARCHAR
...
, c20 VARCHAR
)
CREATE TABLE sales (
k INT /* A unique value allowing us to access individual rows */
, v DOUBLE /* Some value we want to aggregate */
, id_product INT NOT NULL REFERENCES product(product_id)
);Very old school. Let us assume that c01... c20 are some string columns that we happen to know about our products.
To make sure we have a nice chunk of data to operate on, we will use the following cardinalities:
producthas 100_000 rows- each of the
c01...c20columns have ~100 distinct values generated with an MD5 hash
- each of the
saleshas one... billion rows with a random value for thevcolumn and evenly spread outid_productvalues
Of course, we will typically have more structure in the data than this uniform randomness. But this gives us a baseline
of entropy without having massive cardinality of the cNN columns (which would be unfair to the OBT model).
The model we have here, where the entity (product) has its attributes moved into a separate table from sales,
is called a "dimensional model". More about that later.
Generating data for the dimensional model
First, we make sure we have a seed table. Most databases have number style tables, but they do not have a standard way to generate a sequence of numbers. The below method works on "all" SQL platforms:
CREATE TABLE seed10 (
n INT NOT NULL
);
INSERT INTO seed10
SELECT 0 AS n
UNION ALL SELECT 1 AS n
UNION ALL SELECT 2 AS n
UNION ALL SELECT 3 AS n
UNION ALL SELECT 4 AS n
UNION ALL SELECT 5 AS n
UNION ALL SELECT 6 AS n
UNION ALL SELECT 7 AS n
UNION ALL SELECT 8 AS n
UNION ALL SELECT 9 AS n;(side note: YES, I know that I can use INSERT ... VALUES with more than one tuple, but not every analytical database
supports this syntax - I have yet to see a database that does not support the UNION ALL style insert)
With our seed, we can now generate the sales table:
CREATE TABLE sales AS
SELECT
CAST(random() *99999 + 1 AS INT) AS id_product
, random() AS v
FROM seed10 S
, seed10 P10
, seed10 P100
, seed10 P1000
, seed10 P10000
, seed10 P100000
, seed10 P1000000
, seed10 P10000000
, seed10 P100000000
;And product is (The md5 function generates a hex code that is 32 bytes long):
CREATE TABLE product AS
SELECT ROW_NUMBER() OVER () AS id_product
, md5(CAST(1000 +CAST(random()*100 AS INT) AS VARCHAR(32))) AS c01
, md5(CAST(2000 +CAST(random()*100 AS INT) AS VARCHAR(32))) AS c02
, md5(CAST(3000 +CAST(random()*100 AS INT) AS VARCHAR(32))) AS c03
, md5(CAST(4000 +CAST(random()*100 AS INT) AS VARCHAR(32))) AS c04
, md5(CAST(5000 +CAST(random()*100 AS INT) AS VARCHAR(32))) AS c05
, md5(CAST(6000 +CAST(random()*100 AS INT) AS VARCHAR(32))) AS c06
, md5(CAST(7000 +CAST(random()*100 AS INT) AS VARCHAR(32))) AS c07
, md5(CAST(8000 +CAST(random()*100 AS INT) AS VARCHAR(32))) AS c08
, md5(CAST(9000 +CAST(random()*100 AS INT) AS VARCHAR(32))) AS c09
, md5(CAST(10000+CAST(random()*100 AS INT) AS VARCHAR(32))) AS c10
, md5(CAST(11000+CAST(random()*100 AS INT) AS VARCHAR(32))) AS c11
, md5(CAST(12000+CAST(random()*100 AS INT) AS VARCHAR(32))) AS c12
, md5(CAST(13000+CAST(random()*100 AS INT) AS VARCHAR(32))) AS c13
, md5(CAST(14000+CAST(random()*100 AS INT) AS VARCHAR(32))) AS c14
, md5(CAST(15000+CAST(random()*100 AS INT) AS VARCHAR(32))) AS c15
, md5(CAST(16000+CAST(random()*100 AS INT) AS VARCHAR(32))) AS c16
, md5(CAST(17000+CAST(random()*100 AS INT) AS VARCHAR(32))) AS c17
, md5(CAST(18000+CAST(random()*100 AS INT) AS VARCHAR(32))) AS c18
, md5(CAST(19000+CAST(random()*100 AS INT) AS VARCHAR(32))) AS c19
, md5(CAST(20000+CAST(random()*100 AS INT) AS VARCHAR(32))) AS c20
FROM (SELECT 1 FROM sales LIMIT 100000);(side note: YES, we could pick 100 instead of 101 distinct values for c01... c20 - but the above is easier)
That's our first competitor.
The One Big Table Solution
In the other side of the boxing ring, we have our pre-joined - massively wide table. Also known as the "One Big Table" model.
We implement a simple, pre-join of the dimensional model, removing id_product as that is no longer needed:
CREATE TABLE sales_obt AS
SELECT v
, c01
, c02
, c03
, c04
, c05
, c06
, c07
, c08
, c09
, c10
, c11
, c12
, c13
, c14
, c15
, c16
, c17
, c18
, c19
, c20
FROM sales JOIN product USING (id_product);The Hypothesis: Joins are slower than pre-joined tables!
The question we can now ask is, what is better:
The dimensional model asking for all columns:
SELECT v, c01 ... cN
FROM sales
JOIN product USING (id_product) or....The One Big Table (OBT), removing the need for the join and using materialised data:
SELECT v, c01 ... cN
FROM sales_obt If joins are expensive, we should see slower runtimes for the dimensional model - we should also see higher, total CPU cost of joins vs just accessing the materialised data.
I am going to be grossly unfair to the dimensional model and run on a system that has the entire database in memory. That way, we can simulate that we have "infinite I/O" and not pay any cost of issuing I/O requests.
For the first test, I want to use DuckDB. First of all because I think it is a really cool database. Second,
because its EXPLAIN ANALYSE (which they spell correctly) allow us to drill into the rough CPU consumption of
individual operators.
DuckDb Test Setup and Results
I generated the data in DuckDb using the scripts above. I am using my powerful laptop with 14 cores, 32GB of DRAM and a 3GB/sec capable disk drive. That's around the size of a vanilla cloud machine.
The total size of the database ends up at 45GB - with the sales_obt taking up around 40GB of that space.
For our test purposes, we will measure a progression of queries like these:
EXPLAIN ANALYSE
SELECT v
... c01.... cNThe baseline, which I will call "measurement 0" is just reading v which means that we pay the join cost for the
dimensional table, even though we are not fetching any columns from product. Readers who want to understand more
about this edge case, and how to optimise for it, would benefit from reading:
Each query will be measured three times, and we will take the best runtime as the data point.
Initial observations - Wall Clock
First, I note that DuckDB seems to make very good use of the cores. The CPU on my machine is at 100% while the queries are running - very nice.
Let us first look at the wall clock for the Dimensional (dim) vs. the "One Big Table" (OBT):
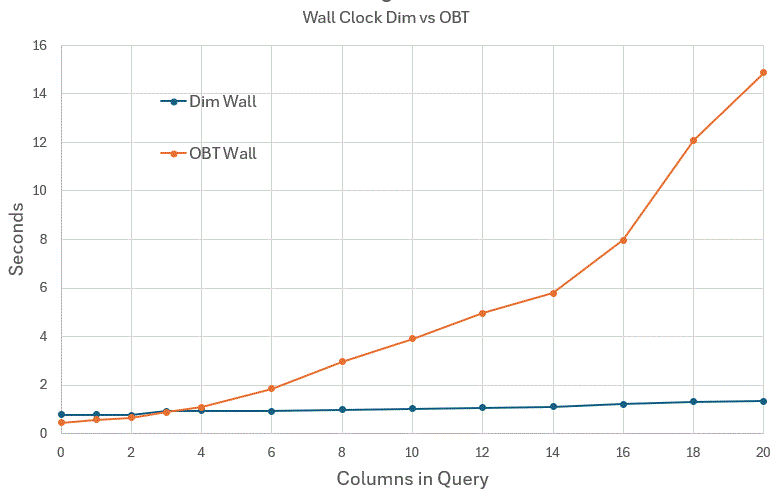
Conclusions so far:
- When you are only retrieving a few columns from the join, it is marginally faster to pre-join
- As the number of columns you can retrieve via the join grows - the cost of OBT models skyrocket
- The join method is highly scalable. Its performance (as we should expect) stays nearly constant as the number of columns we retrieve grows.
- There appears to be something resembles a
O(n log n)cost to the OBT as the number of fetched columns from the wide table grows.
Why is the join faster at scale?
What is going on here? We are retrieving every row in this query. Why isn't it faster to just serve the row directly from the OBT, pre-joined model? And what's with that odd non-linear behaviour of the OBT as the column count grows?
DuckDB, like nearly all modern analytical systems (including those using Parquet) stores data in a columnar format. In order to produce rows for the client - we must:
- Decompress individual columns
- Combine these columns into a memory structure we can operate on
Ad 1) To decompress columns and turn them into user consumable data, we must pay a CPU cost for extracting the actual
column values (that a user can consume) from the compressed format. Compressed strings are typically stored in a
dictionary where the internal, columnar data points at the dictionary. The scan itself is essentially a "join" of pointers
in the compression segments to the dictionary that stores the strings. Consider the alternative: With our product
table, we have already stored all the strings and pre-mapped them into the id_product values - we have in a certain
sense "materialised" the de-compression that would otherwise happen inside the Storage Engine of the database.
Ad 2) Columns are stored sequentially on disk with metadata pointing at the locations of each column. To operate on the data, we must walk through the locations where column are stored (at various offsets) and then copy those sequences of columns into the final result that the database can operate on. There is a non-zero cost of traversing the metadata and reassembling each column segment into the final data results the user requested. Each column typically has its own memory allocation (and later deallocation) too. I suspect that this cost is what we are observing in the non-linearity of the scale curve.
Do joins cost more CPU than scanning?
Fortunately, DuckDb has a neat feature that allows us to measure how much CPU we are spending in each operator in the query. We can break down total CPU cycles (across all 14 cores) into their components.
DuckDB instrumentation allows us to render this:
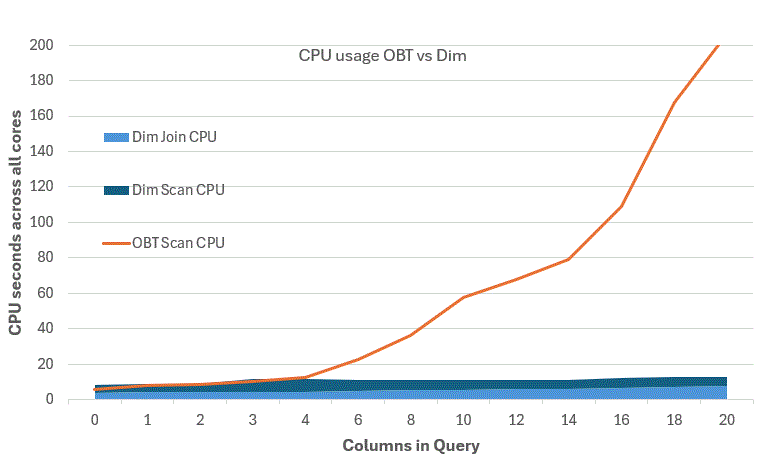
(note: The CPU usage for the dimensional model are stacked so we can see the full cost of scan+join)
Here, you can see the same pattern we saw on the wall clock: The "One Big Table" design, even when we scan all columns, is significantly more expensive (by orders of magnitude) than just joining at runtime - at least when we fetch a lot of column. When looking at total CPU cost of fetching just a single column - the OBT wins, but by an insignificant amount.
Wait a minute!... What about Row Stores?
Not every databases uses columnar compression. In fact, until about 20 years ago, storing data in row based formats (that's AVRO for you Data Lake people) was common.
Row stores have an interesting property that column stores don't: They don't need to "reassemble" the row from the data stored on disk. Of course, as a rule of thumb: row stores typically use more disk space than column stores. They are also poor at retrieving individual columns.
In a world of infinite I/O - is it just better to store the fully materialised data on disk as rows and retrieve it without joins? Is testing joins on column stores putting the OBT model at an unfair disadvantage if we just want to fetch the entire table?
Column stores being cheaper for joins (at least when the size difference between the two join tables is large) was a situation I have seen many times before and I almost take for granted (because of the reassembly problem described earlier). But as I was writing this blog - it occurred to me that I do not have an up-to-date view or intuition of the same question when it comes to row stores:
- "If I/O was infinite - what would row stores look like?"
Here is the way I hypothesised before running the tests below:
In favour of One Big Table (OBT):
- If we store rows in "one big table" we can retrieve them directly without any cost of "row reassembly" from de-compression
- That should make the scan part of the query cheaper and completely avoid the "implicit join" that occurs during a column store scan when decompressing strings.
- Joining on row based layouts is slower than on a columnar layout - because you cannot vectorise the hash/probe calculations
In favour of joining and dimensional models:
- If I only fetch a fraction of the columns, would projecting the columns I actually want cost more?
There is an implied
memcpyhere as we discard part of the row to give the user the requested columns. - Even with infinite I/O - there is a non-zero cost associated with a scan accessing chunks of data and the amount of memory we need to juggle is higher - potentially leading to more overhead accessing buffers during the scan.
- The join has much better cache locality for the strings, which means we churn through less memory and may in fact have FEWER TLB misses as we access the data
- Of course, I/O isn't actually free, particularly not in Object Stores - so there is probably some HTTP overhead that costs CPU that might skew the results further.
Putting all this together, my intuition tells me that row stores might move the "crossover point" further away from a single column and favour OBT designs more - at least if all you do I retrieve the data.
Let's test it shall we?
Putting row stores to the Test
It's hard to find a row store analytical system these days. But I am mostly curious about the general shape of the scale curve and to see if my intuition about crossover points for row stores is right.
Hence - I picked PostgreSQL (version 17). You all have access to such a database - and it is a row store implementation has stood the test of time... Or something...
I want to eliminate the cost of I/O when I measure this. As you will soon see, Postgres is orders of magnitude slower
than DuckDb for analytical queries. Hence, I cut down the generated dataset to 1% of its DuckDb size for sales / sales_obt bringing
the size to a meager 10_000_000 rows. I took product down to 10_000 (10% of original size) to avoid giving the
join too much benefit from cache locality. Even at 1% of the original size, sales_obt is still a whopping 7GB (as
opposed to <1GB if we used columnar compression for 10_000_000 rows)/
I had to play a trick to remove the cost of serialising to the client. it appears that PostgreSQL EXPLAIN ANALYSE,
unlike DuckDb, still serialises the result set (into the client format - which is different) before discarding it.
side note: shameless praise for Arrow Buffers where you don't need to do any of that
My hack is this:
EXPLAIN ANALYSE
SELECT COUNT(v), COUNT(c01), ... FROM sales_obt;Just to make sure PG isn't cheating with the implied NULL check we get for COUINT, we can see that aggregate indeed
operates on a row whose width is proportional to the input size:
-> Partial Aggregate (cost=977304.00..977304.01 rows=1 width=16) (actual time=1566.693..1566.694 rows=1 loops=3)In the following, remember that PostgreSQL mostly uses single threaded execution and that we are operating on 1% of the original dataset we put in DuckDb. So don't be scared that the numbers look so slow. All queries were run three times and I checked that no disk activity occurred.
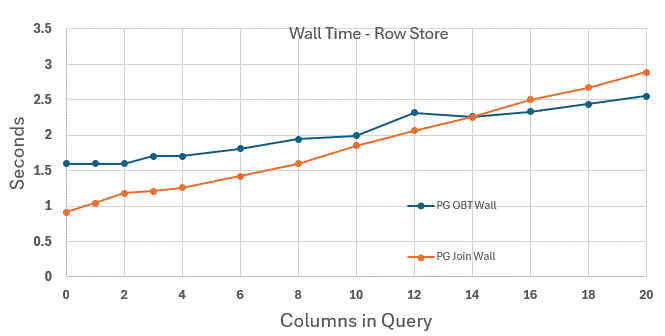
Conclusions
- As predicted,it appears that the cost of projecting away unwanted columns is dominant when the number of requested columns in the OBT is lower than the total number of columns in the table
- In contradiction to my prediction, even the reference case where we pay for the join without asking for column in the hash table. Fetching a low number of columns is also better in the dimensional model.
- Notice the beautiful linearity (i.e. good scale) for the row store even as the column count grows. Both for OBT and Dimensional models
Again, we observe that even when the OBT design wins (which it doesn't a lot) - the difference with the join case is tiny. Though we also see the trend that as the table goes super wide, that gap may increase.
Digging deeper into PostgreSQL
I was curious to know if PostgreSQL is a "fair" representation of a row store. In particular, what it was doing with its time just scanning through rows already in row format (i.e. the OBT case). I was legitimately surprised that OBT does not do better in row stores.
Time to rollup my sleeves. I used Windows Performance Recorder to grab stack samples from PostgreSQL while it was running that 16 column, crossover data point. I had to do some hacking to get symbols working on Windows - see the sidebar if you care.
Using EXPLAIN (ANALYSE, BUFFERS) I made sure I was hitting the table purely in memory - as witnessed by this output:
Aggregate (cost=1434136.80..1434136.81 rows=1 width=136) (actual time=5645.133..5645.134 rows=1 loops=1)
Buffers: shared hit=909120
-> Seq Scan on sales_obt (cost=0.00..1009123.20 rows=10000320 width=536) (actual time=0.017..1161.646 rows=10000000 loops=1)
Buffers: shared hit=909120The trace is set up with First Level triage and CPU Usage options in the Performance Recorder.
Since PostgreSQL forks on connections, we can actually see the query we are running as a process in
the trace. You can get the process your connection currently is with: SELECT pg_backend_pid();... Very 1980s...
We can now drill into the trace and get this:
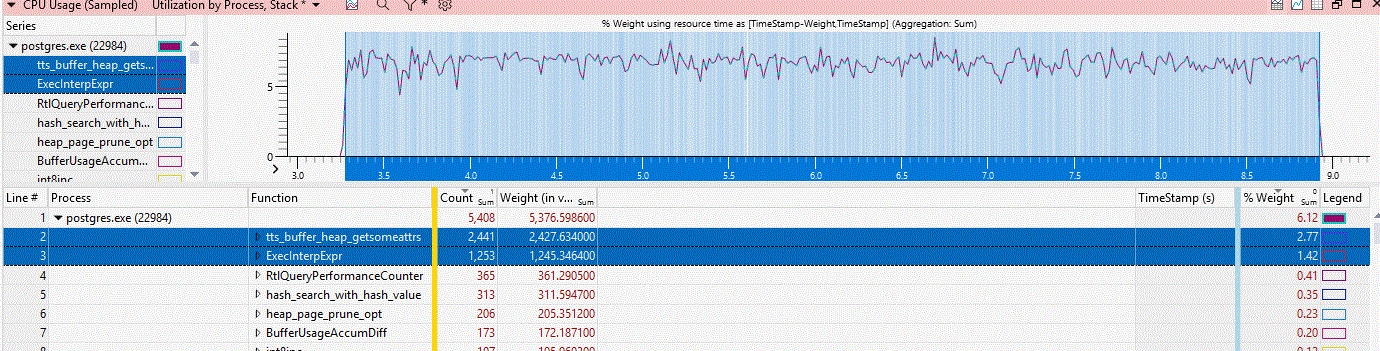
We notice that two functions are hot (and only one CPU is active - but that's just PostgreSQL)
tts_buffer_heap_getsomeattrsExecInterpExpr
Ad 1) Reading this function in the source (location: src/backend/executor/execTuples.c) reveals something worrying.
The function is essentially a clunky memcpy. It moves memory from the buffer pool into the tuple representation.
Remember that I predicted there would be a memory copy to project the rows into the requested data? But not a slow
implementation like this!
Ad 2) This one (at: src/backend/executor/execExprInterp.c) is probably enough material for its own blog entry. What is
happening here is an interpretation of an expression. Many modern databases uses either
vectorised execution or compiled expressions. Postgres still uses interpreted code. Think JavaScript vs.
C++ - you get the general idea. What we have here is a gigantic switch statement. If we reverse the call graph
in Performance Viewer, we can see that the most CPU hungry caller is ExecAgg - interesting! It is almost as expensive
to do that COUNT, as it is to read the data!
Conclusion about PostgreSQL as a Row Store data point
We have seen that a row store has a different crossover point than a column store when it comes to "joining is expensive". It would seem that row stores should nearly always favour joins, unless you plan to pick nearly every column in the OTD on every query. Lending more fuel to my original statement that OBT designs are inferior for nearly all cases.
However, we have also seen that PostgreSQL takes a CPU intensive (and far from optimal) path when reading data from its buffer pool. It could be the case that other databases with row stores, particularly those that compile queries, would be significantly faster at "raw scanning" data. We might see the crossover point move, so joins are more expensive in the leftmost part of our graphs. One would certainly hope so! Because if not, everyone who has ever de-normalised a column to save CPU cycles would be wrong.
TL;DR: We should not be too eager to draw general conclusions about row stores from the PostgreSQL test.
Once again forgetting the past: Dimensional Models
We have observed that joining is generally faster and less CPU hungry than big, wide table models. We have seen that this is certainly true on optimised columnar engines like DuckDb. We have also seen that if you fetch a single column from a join - storing that value in a wider table might be slightly better. There is a crossover point here - around 1-2 columns from the remote table. What we have also seen is that even when the join is slower - its a very small effect.
As tables get wider - we also saw that the cost of scanning many columns in those tables grows non-linearly. In a practical sense of the word: large, wide tables do not scale!
Interestingly, none of this should be a surprise to anyone who paid attention to the history of data. Already in 1996, Ralph Kimball published: "The Data Warehouse Toolkit: Practical Techniques for Building Dimensional Warehouses". New editions are still in print today and I highly recommend you pick up a copy.
In his book, Kimball makes the case that data models for analytical purposes should use joins to access data. But those joins should be designed in a very specific way. He argues that the large tables in the analytical systems (which he calls "facts") should only contain measurements (=things you aggregate on) and "dimension integer keys" (=things you join on). Dimension integer keys point, via foreign keys, at "dimension tables" which contain every single attribute we care about for each entity that is related to the fact table.
Kimball also argues that dimensions with a single column, particularly ones with high cardinality - are best stored directly in the fact table - instead of moving them into a dimension table. He calls this concept: "Degenerate dimensions". It maps perfectly only our observation that fetching a single column via a join is in fact slower than not joining at all.
Did Kimball make all these architectural advances just to save space in large tables? Did the advent of the cloud make these observations about computer science and computational complexity irrelevant? Of course not! Like data modellers before him - he must have been aware that joining to reconstruct data is in fact cheaper than pre-joining all data - even if you have infinite I/O and storage.
Kimball also makes the case for pre-joining tables related to a dimension into the dimension table itself. This makes the dimension table wider and a bit more "OBT like". But he only does this for the dimensions, the tables that end up being joined to the facts. He does this, not for reasons of performance, but because it makes the job of query optimisers easier (and we will see why one day when I find the time).
Summary
What are we to make of all this?
If you take one thing away from this post - it should be this:
- "Joins are NOT expensive compared with the alternatives"
We have seen that even when you read the entire table - join are often cheaper than One Big Table. Obviously, this statement comes with some qualifications. For example, as Kimball's insights might allude to: We have yet to see what happens if you join two really large tables with each other. We have so far only seen a large (1B row) and a small, 100_000 row table).
We have not yet spoken about the performance differences observed once you add filters to the data. Spoiler: The gap between wide tables and joins becomes ever larger and joins win even bigger when we use filters. That will be the subject of my next post: which takes us to bloom filter and push down. When we meet again, we will also pick up TPC-H once more.
Until then - keep the fight going and stay curious!