These days, columnar storage formats are getting a lot more attention in relational databases. Parquet, with its superior compression, is quickly taking over from CSV formats. SAP Hana, Vertica, Yellowbrick, Databricks, SQL Azure and many others all promote columnar representations as the best option for analytical workloads.
It is not hard to see why. But there are tradeoffs.
Row Groups
Both column and row based storage will store rows in groups. This optimises disk access patterns. If you stored a single row at a time, you would have to write very small disk blocks every time you want to persist it. Even with modern SSD storage – this isn’t an effective way to access disk. And no, memory mapped files does not get you out of this conundrum – for reasons I might blog about later.
Row Groups in Row Based Storage
In a row based store, the number or rows you store in a row group is typically influenced by the optimal block size of the disk storage you use. The optimal block size for traditional block storage s in the single to double digit KB. For example, SQL Server will use 8KB and Oracle allows you to use a variable value – but typically one that is between 4KB and 64K.
These small block row groups allow the you to quickly read and change single rows. You simply reada small block from disk (or memory), change its content and writing it back to disk. You may decide to implement compression inside the block. But since the amount of mutual entropy in a KB sized data chunk is normally low. The resulting compression rates is often low too – perhaps 2-3x if you are fortunate.
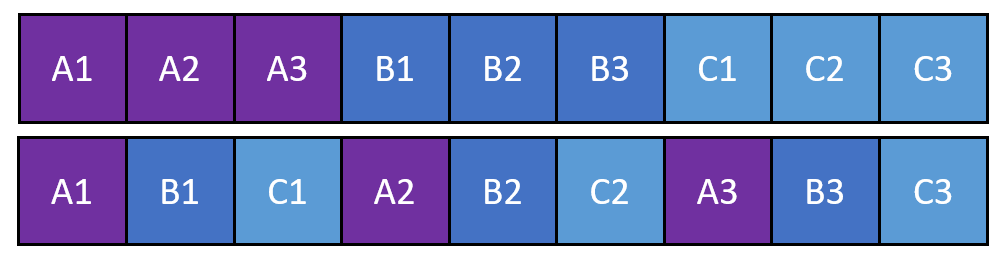
Row Groups in Column Based Storage
In a column based storage, you store each column (sometime groups of columns) in it’s own disk block. That way, you can read (from disk) a subset of columns of the columns making up the table without having to read the entire table.
Consider what this disk layout means when you need to read more than one column from the table. For example, take this simple SELECT statement:
SELECT a, b
FROM Foo
WHERE x = 42To evaluate this statement on a columnar storage, you must read x, a and b from the column based storage. But, you must also eliminate all the a and b values that do not belong in a row where x = 42. If all columns are stored in a long stream on disk without any grouping into the rows they belong to – you will end up performing a massive join between a, b and x column streams based on their row offsets. That’s not very effective. Because of this, your column based storage typically stores a set of rows together in a row group. That way, you can read row group, decompressed it, filter it and recombine the columns into rows without needing to “align” all the columns together across the entire table. You can also have multiple threads fetch row groups in parallel without having to coordinate between the threads.
Consider what this observation means for the arrangement on disk. Each column may compress very differently, depending on amount of entropy in that column. Ideally, you want to store each on its own disk blocks (so you don’t have to read the entire row every time you read a subset of columns).
You seem to have a series of conflicting design requirements:
- Columns compress differently, resulting a variable sized disk blocks
- You want to store columns together in row groups. They way, we can quickly recombine columns to rows.
- You want to store columns individually so we dont have to pay for a full row access if we only want a subset of columns
- You want to have a predictable disk access pattern so we can read large enough blocks to have effective I/O bandwidth
You typically solve this by storing large row groups and packing columns intelligently inside the disk blocks that make up a row group. A column based row group and its disk blocks is typically several MB in size. A single row group may contain millions of rows.
The downside is of course that changes to a single row in a row group require a full rewrite of the entire row group or a large fraction of it.
Column based storage for Analytical workloads
A columnar representation on disk has many advantages over a row based representation for analytical workloads
- When a user
SELECTs a subset of columns, you don’t need to read an entire, potentially larger row. - You typically read a large amount of rows to satisfy an analytical query. This makes the problem of opening big disk blocks a minor concern since you have to access a lot of disk block anyway. If you are in a cloud you may even have to suffer the indignity of a a blob store which works a lot better when you read large blocks.
- In real world data, columns often contain repeated value. When you are compressing by column, the local entropy of data is minimal; there will similar values right next to each other in the column level stream of input data. This typically results in higher compression rates. Your analytical systems typically has a lot of data, at least if its interesting enough for you to care. Column based storage reduces the total disk footprint of the data. You are likely to care about that.
- It is a lot easier to add more columns to a table stored in a columnar format – because you simply append to the existing format. Analytical systems often have data models that change frequently even in the large tables. You don’t want to suffer long downtimes to add a column to a 300TB table.
- Young people nowadays have no clue about 3rd Normal Form modelling and you are probably the unfortunate DBA who has to deal with that. This means your “modern” database models often has very wide tables (thousands of column) that have highly redundant values in each column. In such models, columns are also sparsely populated and contain a lot of
NULLvalues. Column based storage formats does a great job at compressing such data models. - You are training AI models – you can model with BCNF in your sleep – but you chose not to. You realise that your training set is best served by modelling the world as a “big flat table” with each input parameter in the model stored as a new column.
All these factors make columnar storage the preferred way to organise data on disk in analytical databases.
Row based storage for OLTP and Real time Systems
In OLTP databases you care about low latency response times, high concurrency and real time data ingestion. Data changes quickly and all the time. Design parameters like these make the tradeoff between column and row based storage is less obvious. To make matters worse, an OLTP query is typically looking only at a few rows instead of a big set of rows – and you have thousands if not millions of these queries hitting your system every second. You really can’t afford to issue large disk reads for each of them – even if you have the best storage systems in the world.
- OLTP systems are typically in 3rd normal form. You read your Boyce/Codd. Instead of optimising the storage format for quick retrieval of a subset of columns – your data model instead uses
JOINoperations to combine multiple tables into the resulting output. You know that joins are expensive to execute, but you also know that most queries only join a few rows. - Compression adds additional CPU time, which adds latency (this isn’t a given, but more about that in the future). Since OLTP systems tend to be smaller than analytical systems – caching all data in memory (even in uncompressed form) is often a viable alternative to storing highly compressed disk representations. You just care less about compression rates in systems like these.
- Row based formats typically require rewrites of data when adding columns with non default values. This makes data model changes harder to execute. But this is less of a concern to you, because your data model is typically stable or changes slowly. Your hot data sizes aren’t that big anyway – because you are an online transactional database.
- Finding an individual row via a
SELECTstatement in a column based store requires the engine to crack open the entire row-group, decompress it, recombine the columns into rows and return only a small subset of the rows decompressed. In contrast, a row based storage engine can often access a single row with a very small block disk read and just copy the row straight into memory (or keep the entire disk block memory resident). You realise that the extra latency of constructing the row from its column based representation may not be worth it. - To achieve optimal access patterns, column based storage use large row groups. Changing anything in a row group means opening up the entire group, decompressing it, changing the content and then compressing and rewriting the full group to disk. This adds significant latency and amplifies the writing needed for small changes. You realise this has some interesting implications when you change a few rows at a time.
- Appending, for example via an
INSERTstatement, a low number of rows to a row based storage format is very fast. Appending a single row to a column based storage will compress it together with existing rows to form a new row group. This leads to more CPU time and large disk writes, even if you only wrote a single row. That adds latency. - Small, half full row groups introduces a form of fragmentation that must be cleaned up later (typically, but not always, by a background process)
- Changing individual rows with
UPDATEstatements is much faster in row based storage because you can simply change a single disk block or a few addresses in memory (followed by a flush of a single disk block if under memory pressure). The column based storage needs to change a large row group.
- Removing rows in a row group with a
DELETEstatement shrinks the resulting number of rows in that group. Since column based storage operate best when many rows are compressed together,DELETEoperations eventually requires a recompression of row group by combining it with other row groups to form a new, bigger row group. This is an expensive operation that often done as a background process. If that process cannot keep up with the data change rate – the access speed of the columnar storage quickly degrades in a non predictable manner. You really don’t like unpredictability in a real time system.- Row based storage suffers from a similar problem – but at a much smaller scale. Row based storage uses smaller row groups and these groups are much easier to clean up incrementally.
- Appending, for example via an
In summary, your OLTP system that need real time access to data at very low latency (typically in the single digit milliseconds) will often use row based storage. It is faster to change row based storage, its faster to access single rows, and it requires less background operations to keep it neatly packed on disk and in memory. But, you pay when you perform analytical queries and your storage size per row is larger.
Hybrid storage
You probably want to have your cake and eat it too. Which is why hybrid row/column storage is a thing. There are a range of options for mixing up the two strategies that are beyond the scope of this blog entry.
Some ideas to get you thinking
- Could you automatically turn row based storage into column based storage? If so, what criteria would you use to make this choice?
- Does it make sense to turn column based storage into row based storage? How would you decide when to do this?
- What kind of workload are you trying to solve by using a hybrid? Are there assumptions about your workload that make the choices above more obvious?